HTML5 is the latest version of HTML and includes some features that are sufficiently novel to extend the technology. These are the audio, video and canvas tags that support embedded sound, video and graphics.
HTML5 regresses slightly from the strict rules of HTML4 in favor of a less formal approach but it is still essentially a dialect of XML and firmly based on the use of XML tags to represent data types. So they can also be described as elements or nodes. These tags are visible in a text editor but hidden when the page is rendered in a browser window.
Many web pages do nothing other than display content in a structured way and although they may have some functionality in the form of hypertext links, they are essentially static presentations. They can become dynamic by adding functionality, or behavior, so that they do something, usually in response to user input. This functionality is provided by a program, which for web pages can be described as a web application. So the web page can be identified as the user interface of a web application.
The web application differs from native applications written for desktop and mobile systems, which run entirely on the host platform. These include the usual range of word processors, databases and mobile apps. Web applications are based on a split architecture. The user interface is on the client, which is the browser, and the functionality may be located on the server or the browser or both. Client functionality is usually written in Java (in the form of applets), or Adobe Flash, but for HTML5 it is written in JavaScript, and this is one of the defining features of HTML5.
The main difference between these two types of client side technologies is that Java and Flash require plugin modules to be installed in the browser. This allows them to be largely independent of which browser or platform is being used and enables powerful applications to be developed. JavaScript, on the other hand, is executed by the browser itself without any plugins. For this reason, Java and Flash are excluded from modern mobile systems which require lightweight applications that do not allow plugins to be installed. On the other hand, JavaScript applications must be written to run on many different browsers all with their own interpretations of HTML5, which is the main problem with JavaScript programming.
In fact, HTML5 is a term that is usually taken to include JavaScript and other technologies as well as the basic HTML5, and this diversity of implementation applies to all of them. In this website we cover HTML5, JavaScript and other ingredients, such as Cascading Style Sheets (CSS).
A web page is a text file with the extension .html or .htm. It can be read by a browser or a text editor. In the first case, it is rendered as a web page but in the latter case, it is displayed as a text file that shows the underlying HTML source code. This is what is parsed by the browser to display the web page.
To create a web page you can use a simple text editor such as the ones provided with Microsoft and Mac operating systems. Or you can purchase an editor such as Dreamweaver which shows both versions of the page. Or you can obtain a free text editor that does a better job than the built-in applications such as notepad++ and view your page separately in your browser.
There are two ways to view the content of an HTML page. One is in a browser, where it looks like a web page. You can load it as a file or download it from a web server. The other way to view it is in a text editor, where only the underlying source code is displayed. This is what is parsed by the browser to produce the web page. In either case, the page is contained in a file with the extension html, or htm.
The page can be edited as HTML code in a text editor and saved with the.html extension then read as a web page in a browser. Such editors are provided free with Microsoft and Apple operating systems but there are better options available as free downloads, such as notepad++. The important feature is that they do not insert any formatting that would confuse a web browser.
Then, the procedure adopted here will be to edit the file in the text editor and view it in a browser, or preferably several browsers to see any differences. Of course, there is also the more expensive option of a commercial wysiwyg editor such as Dreamweaver but even with this you would be well advised to test your work in real browsers.
Although not visible in a browser, the entire content of a web page is contained within a structure of tags. These are exactly the same as XML tags but are not user defined. HTML tags are limited to a fixed set that is recognized by a browser. In fact, one of the major innovations of HTML5 is the addition of new tags.to the existing set.
A tag is a key word enclosed in angled brackets. The main tag is the <html> tag which signals the beginning of a web page and its matching </html> tag which adds a forward slash to denote the end of the page. Nested between these tags is the content of the page, split into two consecutive sections representing the head and the body of the page. These are defined as a <head>,</head> pair followed by a <body>,</body> pair. The head contains general data about the page while the body contains the content that is to be displayed. The whole structure is preceded by a document declaration tag which tells the browser what version of HTML is employed. For HTML5 this is <!doctype html> so the entire page is contained within the structure,
<!doctype html>
<html>
…
</html>
<body>
…
</body>
</html>
HTML code is not case sensitive, so all of these tags can be written in lower or upper case, and they can be indented with tabs or spaced out with blank lines to make the code more readable. The only times when HTML is sensitive to blank spaces is when they break up a key word, such as a tag name, or occur in an actual string of text characters.
There are many tags, such as the three examples above, that come in pairs. There are others that are just single tags that may or may not close themselves with a forward slash. These will be introduced in the following chapters as they are required but for the present, here is a basic working set to get us started.
Paired tags are containers for other elements. They must always be nested. That is, each pair must open and close inside any outer containing pair. They include
<html></html> enclose the html document
<head></head> enclose the head of the document
<body></body> enclose the displayed body of the document
<p></p> enclose a paragraph of text
<h1></h1> encloses text to be displayed in the largest font
<h5></h5> encloses text to be displayed in the smallest font
<b></b> display the enclosed text in a bold font
<i></i> display the enclosed text in an italic font
<h1></h1> important text formatted as the browser prefers
<a></a> anchor tags that contain hyperlinks
<title></title> contains the title of the document (head element)
<ul></ul> contains an unordered bullet list of items
<ol></ol> contains an ordered numbered list of items
<li></li> contains the text for an item in a list
<form></form> contains elements of a form for user input
<div></div> contains elements to be treated as one group
<iframe></iframe> contains material that behaves as an embedded page
<script></script> contains JavaScript code or file address
<style></style> contains a stylesheet for the page
<link></link> contains a link to a stylesheet file
<select></select> contains a set of options for selection
<option></option> contains text for a selectable option
<textarea></textarea> contains text input by the user
<object></object> contains various objects such as Flash apps
<embed></embed> an alternative to object for some browsers
<!—- and --> enclose comments not to be processed by the browser
Single tags can be closed with a /> or in HTML5, with just the bracket >. Some common examples are
<br> a line break, often used to create blank lines
<img> the URL of an image file to be inserted
<meta> tags that contain metadata for the web page (head)
<input> allows the user to input data of some sort
Note that the URL, or Uniform Resource Locator is the address of the image file and may be an absolute address, such as http://www.billtait.com/Images/Image.jpg or, if the location is on the same server, it may be a relative URL such as Images/Image.jpg.
Since a web page is mainly concerned with displaying text, most of the page content is delivered in elements described as text nodes. These may be nothing more that blocks of text, such as
This is a text node
However, they are usually at the centers of the nested containers. For example, a paragraph might be written as
<p>This is a text node</p>
And contained within bold and italic tags as
<b><i><p>This is bold italic text</p></i></b>
Note that the order in which these tags are opened is not important as long as they are closed in the reverse order to maintain the nesting structure.
Also, this is one of the occasions where blank characters do matter since they are displayed in the browser window, even if they are inserted just before and after the text string. There are no bank spaces between the text and the paragraph tags.
And one last point to note is that there are no quotation marks around a text node. If it is tag-free it is a text node.
As you probably know, HTML does not allow the insertion of more than one blank character in a text string. It will ignore any extras. And it does not recognize new lines in the text. You have to use the break tag, <br> twice to get a blank line.
One problem with text nodes is that there are some special characters that are used by HTML and if they turn up in a text node they will be interpreted as HTML. These include the < and > brackets. The only way around this problem is to replace these characters with alternate codes which for < and > are < and > respectively.
These tags may also contain further information in the form of attributes. Each of these is defined as a name and value pair inside the opening tag. Again there are very many of these so a basic list is all that can be presented here just to illustrate the concept and provide a working set. Further information can be obtained from the w3schools site.
An important example is the hypertext anchor tag <a> which must have the href attribute to specify the target url of the page to which the hyperlink is connected. Also,it usually contains a text node that is the clickable part of the element and is displayed in some highlighted way to indicate that it is clickable. So for example, we might have
<a href=nextPage.html>Click to go to the next page</a>
Note that you can also include the value in quotation marks and in fact have to do so if the value has any spaces in it. In this book we will tend to use the quotes since they make the structure slightly clearer. So it is common to write
<a href=”nextPage.html”>Click to go to the next page</a>
Another common attribute is the source url for an image file to be inserted in the web page on download. This is added to the <img> tag as a src attribute, for example,
<img src=”images/firstImage.jpg”>
where we have used the quotes this time and referred to an image located in an images folder in the same folder as the web page.
An important point to note this time is that in this case, the image file must be stored on the web server in the images folder. You can refer to any images in any folder and any website.
Finally, the last example of the use of attributes is one that is vital to the use of JavaScript and CSS with HTML5. This is the <div> tag and its id attribute.
<div id=”Heading”>The heading of my article</div>
In fact the id tag is an identifier attribute that can be used in any tag and is required if the tag is to be processed in some way by a JavaScript program or a style sheet. It must be unique in the document so that this can happen. It is the name of a particular tag object.
You can also have more than one attribute in a tag. For example, an image tag can have the src, an alt for alternate text, and a width and height to which the displayed image is to be scaled. This process does not preserve the original aspect ratio so the original will be deformed if it differs from a 4:3 ration used in this example. These attributes are written as a series of name-value pairs separated by space characters.
<img src=”Dockands.jpg” alt=”Picture of London docklands” width=”320” height=”240”>
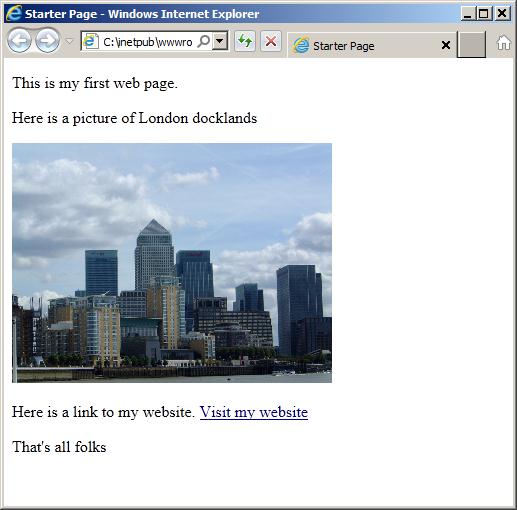
Finally we can use an example to illustrate the HTML code and the displayed website. This page uses some of the example code snippets described above and was written in Notepad++. If you are reading this in color you will see that Notepad conveniently color codes the various types of entry which greatly helps in avoiding typing errors. The file is saved as Starter.html in a convenient working folder and the image, Docklands.jpg is saved in the same folder. It is a 1024 by 960 pixel image which is scaled down to 320 by 240. This is not a good idea because the large image still has to be downloaded with the website taking more bandwidth than necessary. It is done here just to illustrate the process.
The code is listed below and the rendered page is illustrated in Figure 1. It is obtained by opening the browser and selecting file open or, in Windows, by double clicking on the html file which opens it in the default browser, which is much easier.
<!doctype html>
<html>
<head>
<meta charset="utf-8">
<title>Starter Page</title>
</head>
<body>
<p>This is my first web page.</p>
<p>Here is a picture of London docklands<p>
<img src="Docklands.jpg" alt="London docklands" width="320" height="240">
<p>here is a link to my website>
<a href="http://www.billtait.com">Visit my website"</a>
<p>That's all folks</p>
</body>
</html>
The code uses an HTML5 doctype declaration then in the head of the document uses a meta tag to define the language used, again in HTML5 and a suitable title for the page. In the body it delivers a text node in paragraph tags, then the image, suitably scaled down, some more text, then a hyperlink to another website and a final text node.
To use HTML5 you must start the document with a doctype declaration of the form <!doctype html>. Then it will be recognized as HTML5 by all browsers. It is also a good idea to use the language meta tag described in the above example. Other than that, the main differences between HTML5 and previous versions are
In fact, the first two don’t amount to much of a change and to make sure the document displays correctly in all browsers it is quite common practice to use the XML syntax which still functions perfectly. This means you can use lower case tag names and quoted attribute values, and you can continue to close paragraphs with the </p> tag and single tags with /> instead of >.
Also you can avoid using most of the new tags and stick to the old <div> tags with semantic id values instead. For example <div id=”article”> is safer than <article>. If you do use the new tags, and you will have to use some of them such as the <audio> and <video> tags then you should test your page in a range of popular browsers to make sure they work.
Semantic tags are just tags with clear meanings. They allow the author and the search engine agents to clearly understand what each tag does. They include the following:-
<article></article> a large section forming an independent article
<figcaption></figcaption> the caption to a figure
<figure></figure> a figure to be displayed
<footer></footer> a footer for the page
<header></header> a header for a page
<nav></nav> a section containing navigation controls
<section></section> a generic section
In addition we now have
<audio></audio> contains a link and controls to an audio file
<video><video> contains a link and controls to a video file
<canvas></canvas> an area in which graphic content can be drawn.
These last three are possibly the most important HTML5 features since they replace Java and Flash alternatives of which the latter, at least, is very widely used. They convert web pages to web applications and are the reasons for abandoning Flash in favor of HTML5.
However, the audio and video tags in particular are not uniformly implemented by all browsers, especially with respect to the audio and video codecs or file types they can accommodate. They replace the less semantic <embed> and <object> tags that you may have been using. This is a substantial disadvantage compared to Flash but the HTML5 approach is more future-proof and will prevail as browser conformity is improved.
Meanwhile we can deal with the problem by utilizing the property of HTML that causes it to ignore tags that it does not recognize. It does not crash at these tags but just carries on regardless. So if we present a browser with two sets of tags it will only use the one it recognizes. It means we do have to deploy our audio and video files in at least two versions but this is a small price to pay for progress.
The canvas is more reliably implemented by all browsers including mobile ones so it can be used to add the graphic content and animation that until now has been HTML’s missing ingredient.
You can learn more about HTML5 in my book "Start Programming with JavaScript" published in Kindle and paperback format by Amazon.